Motion Modes is the first training-free method to generate multiple plausible yet distinct motions for a given object, disentangled from the motion of other objects, camera and other scene changes, from a single input image.
What are the different ways the object could move?




























Click here to view an extensive qualitative comparison to several baselines.
Categorized Results
Animals






























Articulated objects


























Automated vehicles
























Complex flows





























Rigid movement




























Click here to view additional qualitative results.
Overview
Predicting diverse object motions from a single static image remains challenging, as current video generation models
often entangle object movement with camera motion and other scene changes. While recent methods can predict specific
motions from motion arrow input, they rely on synthetic data and predefined motions, limiting their application to
complex scenes.
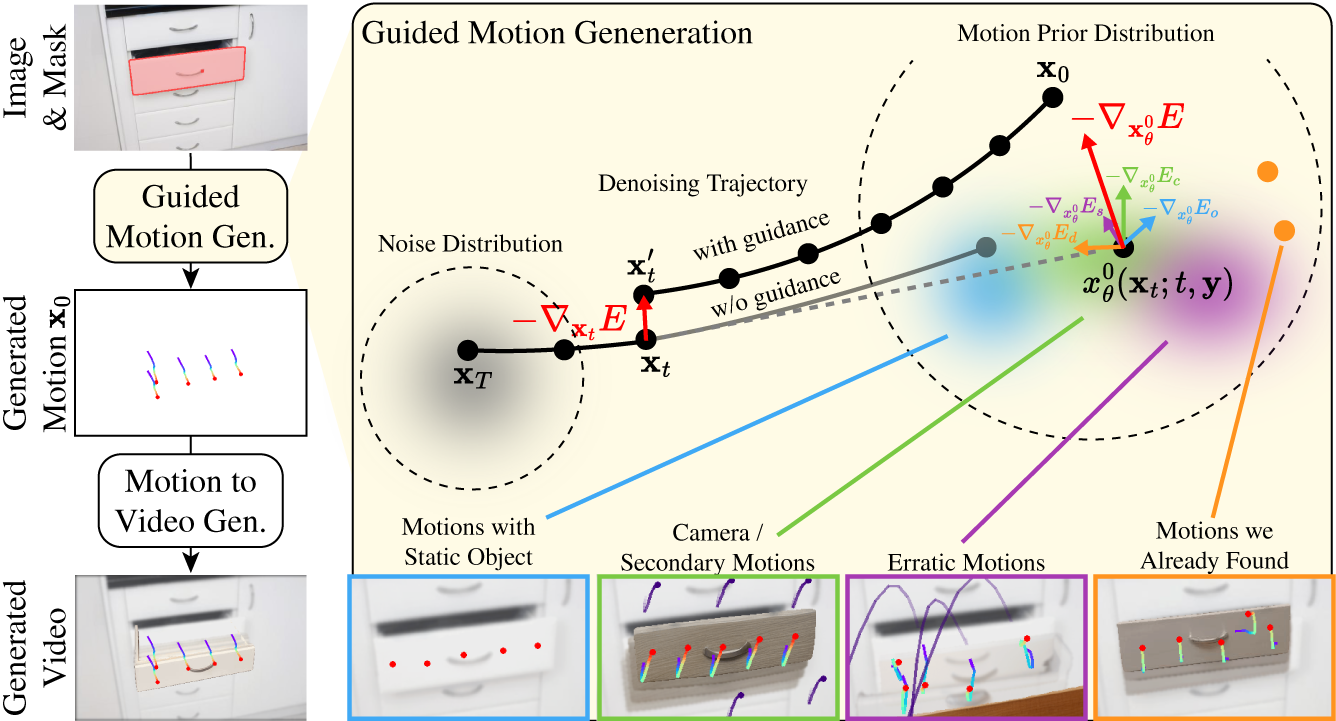
We introduce Motion Modes, a training-free approach that explores a pre-trained image-to-video
generator's latent distribution to discover various distinct and plausible motions focused on selected objects in static
images. We achieve this by employing a flow generator [1] guided by energy functions designed to disentangle object and
camera motion.
Additionally, we use an energy inspired by particle guidance [2] to diversify the generated
motions, without requiring explicit training data. Experimental results demonstrate that Motion Modes generates realistic and
varied object animations, surpassing previous methods regarding plausibility and diversity.
Code will be released upon acceptance.
Applications
Our discovered motions can be used to plausibly constrain, correct and complete drag-based user inputs to image and video editing methods. Here, we present results of motion completion on Image-to-Video models: Motion-I2V [1] and MOFA-Video [3].
MOFA-Video [3]
Input
w/o Motion Modes
w/ Motion Modes (Ours)
Image
User Drag
Output
Snapped Drag
Output
Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Motion-I2V [1]
Input
w/o Motion Modes
w/ Motion Modes (Ours)
Image
User Drag
Output
Snapped Drag
Output
Input

User Drag

w/o Motion Modes

Snapped Drag
w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

Input

User Drag

w/o Motion Modes

Snapped Drag

w/ Motion Modes (Ours)

References
[1] Shi, X., Huang, Z., Wang, F.Y., Bian, W., Li, D., Zhang, Y., Zhang, M., Cheung, K.C., See, S., Qin, H. and Dai,
J., 2024, July. Motion-i2v: Consistent and controllable image-to-video generation with explicit motion modeling. In
ACM SIGGRAPH 2024 Conference Papers (pp. 1-11).
[2] Corso, G., Xu, Y., De Bortoli, V., Barzilay, R. and Jaakkola, T., 2023. Particle guidance: non-iid diverse
sampling with diffusion models. arXiv preprint arXiv:2310.13102. [Appeared in ICLR 2024]
[3] Niu, M., Cun, X., Wang, X., Zhang, Y., Shan, Y. and Zheng, Y., 2024. MOFA-Video: Controllable Image Animation via
Generative Motion Field Adaptions in Frozen Image-to-Video Diffusion Model. arXiv preprint arXiv:2405.20222. [Appeared
in ECCV 2024]